AgentDiff is a CLI tool that hooks into Claude Code and tracks every file change with its prompt, reasoning, and task context. Think git blame, but for the why behind AI-generated code. Works with any language, any codebase.
Point at any line and see who wrote it (agent or human), the prompt that caused it, and the reasoning behind the change. Agent metadata is automatically attached to commits as git notes, so PR reviewers get the full context without leaving git log.
LLMs show their reasoning. Agent-written codebases are still black boxes.
Why I built this
I've shipped more code in the last three months than in the previous year. Not just at work. I've been building side projects I actually use: local VLMs on iPhone, Mac apps, inference optimizations, AI research finder. Claude writes it, I approve it, and it works. That's the problem. It works so well that I stopped questioning it, and somewhere in there I lost track of my own codebase.
I can read every line of code Claude writes. It's clean, well-structured, legible. And I still have no idea why it looks the way it does. The decisions that shaped my codebase happened inside conversations I've already forgotten. Things move so fast that my brain can't retain the reasoning behind code I approved three days ago. And it's not just me. I started noticing the same thing in my colleagues' code. PRs where the author can't explain the architecture. Reviews where nobody questions the patterns because nobody chose them deliberately. The model's output is transparent. The decisions behind it are invisible.
Comments are supposed to help. Git is supposed to capture the evolution of code. But when the agent made 40 decisions before you committed, none of that works. Git can't tell you which prompt caused which line, whether the agent stayed on task, or if it even consulted your spec. git blame points at you. But you didn't write it. You approved it.
git diff
→
what changed
git blame
→
who changed it
agentdiff blame
→
why the agent changed it
This is what's actually happening. The agent makes dozens of decisions it never tells you about. JWT over sessions, bcrypt over argon2, environment variables over a config file. You didn't ask for any of those choices. You didn't evaluate the tradeoffs. But they're in your codebase now, and six months from now a new developer will assume a human made them deliberately. They'll build on those assumptions. These are your codebase's accidental architecture decisions: defaults a model picked in 15 seconds that become load-bearing walls nobody knows how to move.
Meanwhile the agent is touching things you didn't ask it to touch. You want one feature and it also refactors a module, updates three test files, changes an import convention. Some of that is helpful. Some of it introduces bugs you won't discover for days. You can't tell the difference because the diff was 400 lines and you skimmed it.
And the link between what you wanted and what got built is already gone. You had a spec. You wrote a prompt. The agent wrote code. That chain (spec → prompt → code) exists in your memory for about 20 minutes.
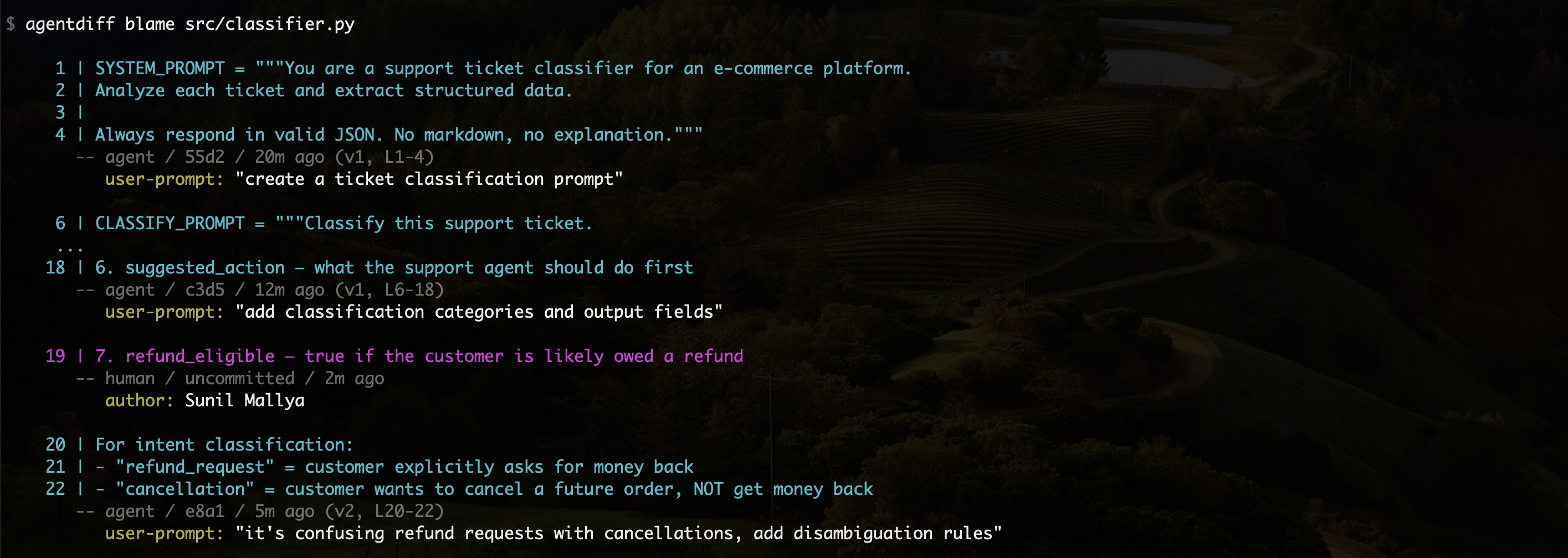
Human + Agent Iterations
Real vibe coding is iterative. The agent writes code, you tweak it, the agent refines it. AgentDiff tracks both sides. Every line shows who wrote it (agent or human), the prompt that caused it, the agent's reasoning, and which section of your spec it maps to.
$ agentdiff blame src/auth.py
1 | from flask import request, jsonify
2 | import jwt, os
-- human / uncommitted / 3m ago
author: Sunil Mallya
4 | def login(email, password):
5 | user = db.users.find_one({"email": email})
6 | if not user or not check_password(password, user["hash"]):
7 | return jsonify({"error": "Invalid credentials"}), 401
8 | token = jwt.encode({"user_id": str(user["_id"])}, os.environ["SECRET_KEY"])
9 | return jsonify({"token": token})
-- agent / a1f3 / 5m ago (v1, L4-9)
user-prompt: "add login endpoint with JWT"
reasoning: "Implemented email/password login that returns a signed JWT.
Uses bcrypt hash check and reads SECRET_KEY from env."
11 | def require_auth(f):
12 | def wrapper(*args, **kwargs):
13 | token = request.headers.get("Authorization", "").replace("Bearer ", "")
...
22 | return wrapper
-- agent / a1f3 / 2m ago (v2, L11-22)
user-prompt: "add auth middleware to protect routes"
reasoning: "Added decorator that extracts and validates JWT from the
Authorization header. Attaches user_id to request context
so route handlers can access the authenticated user."
spec: SPEC.md -> ## Authentication
The agent silently hardened your JWT decode against algorithm confusion attacks. Good decision, but this is exactly the kind of accidental architecture that accumulates. Without a record, six months from now someone will see algorithms=["HS256"] and assume it was a deliberate security review. It wasn't. It was a model default. And if it's ever wrong, nobody will know to question it.
Run agentdiff blame <file>:<line> --history on any line to see its full evolution. In the hero example above, line 17 starts as a bare jwt.decode() call (v1), then the agent pins it to HS256 to prevent algorithm confusion attacks (v2). Each version captures the reasoning behind the change. Agent-written lines preserve their prompt and reasoning, and human edits are detected automatically via git diff. Only the lines you actually changed show as human. No attribution is lost.
When you commit, AgentDiff attaches all of this as git notes. The notes travel with the commit, so PR reviewers see the agent's reasoning directly in git log without any extra tooling. CI pipelines can read the notes to flag commits where the agent worked outside scope or made decisions that weren't in the spec. The context that used to vanish after your coding session now lives permanently in your git history.
How does it work?
Write / Edittool calls
PostToolUseSubagentStartStop
active task, spec
match, file diffs
per session file,
append-only
generates reasoning
for PRs & CI
git diffagent vs human per line
works before commit
Watching the filesystem only tells you what changed, not why. So instead, AgentDiff intercepts the agent's tool calls directly. Claude Code has a hooks system that fires lifecycle events on every Write, Edit, subagent start/stop, and session end. AgentDiff registers hooks on these events and pipes the event JSON to a local daemon over a unix socket. Under 5ms per hook, fail-open, invisible during coding.
The daemon records each change as a JSON line with everything git would lose: the prompt that caused it, the active task, which spec heading it maps to. One line per change, append-only, no database. At session end, a single API call to Claude Code generates concise reasoning summaries for all changes at once.
agentdiff blame reads the live change log, so it works before you commit. When you modify agent-written code in your editor, AgentDiff uses git diff to detect which lines you changed. Only those lines show as human. Agent-written lines you didn't touch keep their original attribution.
On commit, git hooks attach the full change context as git notes. The notes travel with the commit and show up in git log, so PR reviewers see agent reasoning without extra tooling. The chain from uncommitted changes to blame to commit to PR is unbroken.
Why this is possible now
If you've used Claude Code over the past few months, you've probably noticed something: the agent's behavior has become remarkably structured. It doesn't just generate code in a stream anymore. It thinks, plans, breaks work into subtasks, calls specific tools (Write, Edit, Read, Bash), completes a subtask, and moves to the next one. There's a predictable execution loop: receive prompt, plan approach, execute tool calls, verify, report back.
That structure is what makes AgentDiff possible. Two years ago, AI code generation meant pasting output from a chat window. No tools, no events, no lifecycle. You'd have to diff files and guess which prompt produced which change. There was nothing to hook into.
Now Claude Code fires typed events for every tool invocation: which file was written, what was edited, when a subtask started and stopped. The agent's execution loop is observable. AgentDiff doesn't guess from file diffs. It intercepts the agent's actual operations as they happen, with full context about the prompt, the task, and the intent.
As coding agents mature, this structured tool-call pattern is becoming universal. AgentDiff is built for Claude Code today, but the architecture generalizes to any agent with observable tool use.
Get started
AgentDiff is language agnostic — it tracks changes to any file type (Python, TypeScript, Rust, Go, etc.). The tool itself is written in Python for readability, but it works with any codebase.
Install globally so you can use it in any project:
curl -fsSL https://raw.githubusercontent.com/sunilmallya/agentdiff/main/install.sh | shThen initialize in any project directory and start coding:
cd my-project
agentdiff init # registers hooks, starts daemon
# ... code with Claude Code as usual ...
agentdiff blame src/auth.py # see what the agent decided
Every change is tracked automatically. When you're done, run agentdiff blame on any file and see what your agent decided without telling you.
Commands
agentdiff blame <file> # prompt + reasoning per line
agentdiff blame <file>:<line> --history # version history for one line
agentdiff blame <file> --color # color-coded by prompt
agentdiff blame <file> --json # JSON output for scripts
agentdiff log # all changes, newest first
agentdiff log --session=<id> # filter by session
agentdiff log --file=<path> # filter by file
agentdiff tour # generate VS Code CodeTour walkthrough
agentdiff tour --session=<id> # tour a specific session
agentdiff tour --file=<path> # tour changes to one file
agentdiff doctor # check daemon, hooks, config
agentdiff relink # re-match changes to spec headings
Spec linking is optional. Drop a spec_file: SPEC.md in .agentdiff/config.yaml and AgentDiff will match agent changes to your spec headings automatically. Run agentdiff relink after updating spec headings.
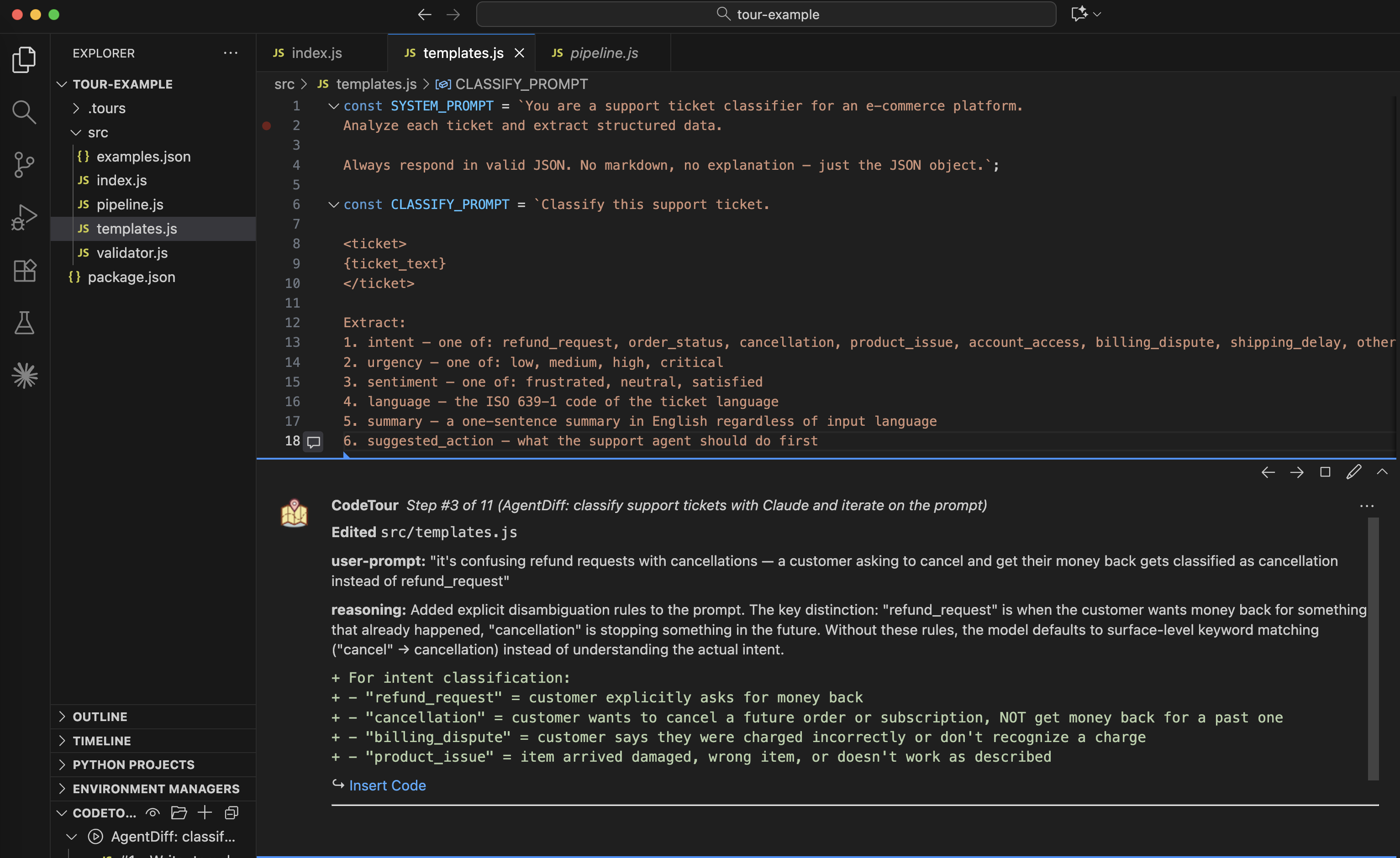
VS Code CodeTour Integration
Instead of building a custom VS Code extension, AgentDiff generates standard CodeTour files — a popular VS Code plugin for code walkthroughs. agentdiff tour produces a .tour file that lets you step through every agent change directly in VS Code, with the prompt, reasoning, and diff shown inline at each stop.
Git gave us version control for code written by humans. AgentDiff adds the layer that's been missing: version control for the decisions made by agents. As more code is written by AI instead of by hand, understanding why code exists becomes as important as understanding what it does.
AgentDiff is open source. MIT license. Python 3.9+.